3.1 테이블 액세스 최소화
- DBA(데이터파일번호 + 블록번호)는 디스크 상에서 블록을 찾기 위한 주소I/O 성능을 높이려면 버퍼캐시를 활용해야한다.
블록을 읽을 때는 디스크로 가기 전에 버퍼캐시부터 찾아본다.
읽고자 하는 DBA를 해시 함수에 입력해서 해시 체인을 찾고 거기서 버퍼 헤더를 찾는다
캐시에 적재할 때와 읽을 때 같은 해시 함수를 사용하므로 버퍼 헤더는 항상 같은 해시 체인에 연결됨
반면, 실제 데이터가 담긴 버퍼 블록은 매번 다른 위치에 캐싱되는데
그 메모리 주소값을 버퍼 헤더가 가지고 있음 - 해싱 알고리즘으로 버퍼 헤더를 찾고 거기서 얻은 포인터로 버퍼 블록을 찾아감.
- 인덱스로 테이블 블록을 액세스할 때는 리프 블록에서 읽은 ROWID를 분해해서 DBA 정보를 얻고
테이블을 Full Scan 할 때는 익스텐트 맵(각 익스텐트의 첫 번째 블록 주소 값을 갖음)을 통해 읽은 블록들의 DBA 정보를 얻는다. - ROWID가 가리키는 테이블 블록을 버퍼캐시에 먼저 찾아보고, 못 찾을 때만 디스크에서 블록을 읽음.(버퍼캐시에 적재한 후에 읽음)
인덱스 클러스터링 팩터
- 물리적 디스크파일에서 데이터가 모여있는 정도를 나타낸다.
예를들어 OLTP의 필수 컬럼으로 날짜가 있는데 데이터가 입력될때마다 날짜로 정렬하듯이 데이터가 입력된다.
이것을 보고 날짜별 Clustering Factor가 좋다 라고한다.
주의할점은 테이블에는 그저 날짜별로 입력이 된것일뿐 DBMS는 이것을 신뢰하지않고 날짜 컬럼으로 index를 만들어야 그 순서를 신뢰한다.
예를들어 obj테이블의 id별로 정렬하여 새로운 t 를 만들었다.
create table t as select * from obj order by obj_id;그후 t테이블의 id 인덱스와 name 인덱스를 두개 만든다.
create index t_obj_id on t(obj_id);
create index t_obj_name on t(obj_name);통계정보를 수집한다.
exec dbms_stats.gather_table_stats(user,'t');데이터를 출력한다.
select i.index_name, t.blocks, i.num_rows, i.clustering_factor
from user_table t, user_indexes i
where t.table_name = 't'
and i.table_name = t.table_name;
| Index_name | blocks | num_rows | clustering_factor |
| t_obj_id | 709 | 50093 | 689 |
| t_obj_name | 709 | 50093 | 24936 |
위에서 본 clustering_factor의 값이 blocks에 가까울수록 CF가 좋고
num_rows에 가까울 수록 CF가 나쁘다.
clustering_factor 값의 계산원리는 아래와 같다.
변수clustering_factor를 선언한다.
인덱스 리프블록에서 처음부터 끝까지 스캔하며 rowid로 블록번호를 취한다.
현재의 블록번호와 전의 블록번호가 다르면 변수값을 +1 한다.
CF로 무엇을 판별하나?
Index Scan의 효율을 판별할 수 있다.
손익 분기점 이라고 부르며, 대개 Index 손익분기점은 5~20% 이다.
100개의 데이터중 5개~20개 까지가 인덱스로 스캔하기 적절하다는 뜻이다.
여기서 CF의 개입이 있는데 CF가 나쁠수록 손익분기점은 1%미만 까지 떨어질 수 있다.
반대로 CF가 좋을수록 90%수준까지 올라가기도 한다.
온라인 프로그램 튜닝 vs 배치 프로그램 튜닝
- 온라인 프로그램
- 보통 소량의 데이터를 읽고 갱신하므로 인덱스를 효과적으로 활용하는 것이 중요
- 조인도 대부분 NL(Nested Loops) 방식을 사용
- 배치 프로그램
- 항상 전체범위 처리 기준으로 튜닝함
- 전체를 빠르게 처리하는 것을 목표로 삼아야 함
- 파티션 활용 전략이 매우 중요한 튜닝 요소이다.(왜? 대량은 Full Scan이 효과적이지만 초대용량은 상당히 오래 기다려야 하고 시스템에 주는 부담도 적지 않음)
- 병렬 처리까지 더할 수 있다면 엄청 좋음!!
sql Trace 보는법

01. Call
- Parse : SQL을 파싱하는 구간. 이 단계에서 새로 파싱하거나 Shared SQL Pool 에서 찾아온 것 까지 포함됨
- Execute : SQL 실행공간. Update, Insert, Delete와 같은 DML문장이 여기수행한 결과가 나온다.
- Fetch : SQL을 통해 나온값을 사용자에게 반환하는 구간
02. Count : SQL문이 Parse/Execute/Fetch 된 횟수
03. CPU Time : Parse/Execute/Fetch 등이 실행한 횟수
04. Elapsed Time : 각 구간에서 시작과 종료까지 총 수행한 시간(단위 : 초)
05. Disk : 디스크에서 블락을 읽은 양(Physical Read)
06. Query : 메모리에서 읽은 블락의 양 (Logical Read)
07. Current : 현 세션에서 작업한 내용을 커밋하지 않아 오로지 자신에게만 유효한 블락(Dirty Block)을 액세스 한 블럭수. 주로 Update, Insert, Delete에서 자주 발생
08. Rows : SQL 수행결과에 의해 엑세스된 ROW 수
09. Misses in library cache during parse : Parse 구간에서 해당 SQL을 Library Cache에서 읽지 못하고 잃어버린 횟수. 값은 1씩 증가함. 값이 1이면 Hard Parse. 0이면 Soft Parse를 의미함.
10. cr (consistent read) : Logical Block Read
11. pr (Physical Read) : Physical Block Read
12. pw (Physical Write) : Physical Block Write
13. time : 수행시간(단위 = 1/1,000,000 초)
IOT (Index-Organized Table)
- Table Random Access가 발생하지 않도록 처음부터 인덱스 구조로 생성된 테이블
- Index leaf block = data block (모든 행 데이터를 리프 블록에 저장)
- 정렬상태를 유지하며 데이터를 삽입(PK 컬럼 순)
CREATE TABLE INDEX_ORG_T (
A NUMBER PRIMARY KEY,
B VARCHAR(10)
)
ORGANIZATION INDEX;
-- 일반적으로 사용되는 테이블은 '힙 구조 테이블'로 ORGANIZATION HEAP; 이 생략되어 있는 것
장점
- 클러스터링 팩터가 좋음
- Random이 아닌 Sequential Access 방식이므로 넓은 범위 access 시 유리
- PK 인덱스를 위한 별도의 세그먼트 생성 불필요
단점
- DML 시 인덱스 분할로 인한 부하 발생 (PK 이외의 컬럼수가 많을수록 성능 저하)
- Direct Path Insert 불가
IOT의 활용
- 크기가 작고 NL JOIN으로 반복 Lookup하는 테이블 (ex: 공통 Code 테이블)
- 폭이 좁고 긴(=로우 수가 많은) 테이블
- 넓은 범위를 주로 검색하는 테이블 (주로 Between, Like 같은 조건으로 검색, 통계성 테이블)
- 데이터 입력과 조회 패턴이 서로 다른 테이블 (ex: 입력은 일자별, 조회는 사원별)
인덱스 클러스터 테이블
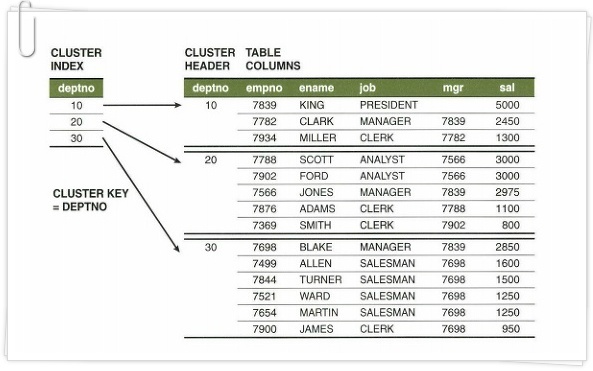
- 클러스터 키 값이 같은 레코드들을 한 블록에 모이도록 저장 (넘치면 새 블록 & 클러스터 체인 연결)
- 물리적으로 같은 블록에 여러 테이블의 레코드 저장 가능 (서로 Join된 상태로 저장->다중 테이블 인덱스 클러스터)
- 클러스터 인덱스는 해당 키 값을 저장하는 첫 데이터 블록만 가리킴
- Key : Record = 1 : M
- 클러스터링 팩터가 매우 좋음
3.2 부분범위 처리활용
- 정렬 조건이 있을 때 부분범위 처리
- array size 조정 통해 fetch call 최소화
- 쿼리 툴에서 부분범위 처리
OLTP 환경에서 부분범위 처리하여 성능개선
3.3 인덱스 스캔 효율화
인덱스 액세스 조건
- 인덱스 스캔 범위를 결정하는 조건절
- 스캔 시작점과 인덱스 리프 블록을 스캔하다가 어디서 멈출지를 결정하는데 영향을 미침
인덱스 필터조건
- 테이블로 엑세스할지를 결정
테이블 필터조건
- 쿼리수행 다음단계 또는 최종 결과집합에 포함할지 결정
옵티마이저 비용 계산 원리
= 인덱스 수직적 탐색 비용 + 인덱스 수평적 탐색 비용 + 테이블 랜덤 액세스 비용
= 인덱스 루트와 브랜치 레벨에서 읽는 블록 수 +
인덱스 리프 블록을 스캔하는 과정에서 읽는 블록 수 +
테이블 액세스 과정에서 읽는 블록 수
비교 연산자 종류와 컬럼 순서에 따른 군집성
- 아래와 같이 예를 들어서 데이터가 있다고 가정했을 때 군집성 확인해본다.
| Root | |||||||||
| branch | branch | ||||||||
| C1 | 1 | 1 | 1 | 1 | 1 | 1 | 2 | 2 | |
| C2 | A | A | A | A | A | B | B | A | |
| C3 | 가 | 가 | 가 | 나 | 나 | 가 | 나 | 가 | |
| C4 | a | a | c | a | b | a | a | a | |
| rownum | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| 조건절3 | 조건절3 | 조건절3 | 조건절1,2,3 | 조건절2,3 | |||||
조건절 1
where C1 = 1 (액세스 조건)
and C2 = 'A' (액세스 조건)
and C3 = '나' (액세스 조건)
and C4 = 'a' (액세스 조건)
조건절 2
where C1 = 1 (액세스 조건)
and C2 = 'A' (액세스 조건)
and C3 = '나' (액세스 조건)
and C4 >= 'a' (액세스 조건)
조건절 3
where C1 = 1 (액세스 조건)
and C2 = 'A' (액세스 조건)
and C3 between '가' and '다' (액세스 조건)
and C4 = 'a' (필터 조건)
조건절 4
where C1 = 1 (액세스 조건)
and C2 <= 'B' (액세스 조건)
and C3 = '나' (필터 조건)
and C4 between 'a' and 'b' (필터 조건)
조건절 5
where C1 between 1 and 3 (액세스 조건)
and C2 = 'A' (필터 조건)
and C3 = '나' (필터 조건)
and C4 = 'a' (필터 조건)인덱스 선행 컬럼이 (=) 조건이 아닐때 생기는 비효율
| 인덱스: 아파트시세코드+평형+평형타입+인터넷매물 where 아파트시세코드 = 'A0101135000056' and 평형 = '59' and 평형타입 = 'A' and 인터넷매물 between '1' and '3' > 아파트시세코드, 평형, 평형타입이 = 조건으로 비효율 없이 스캔 |
| 인덱스: 인터넷매물+아파트시세코드+평형+평형타입 where 아파트시세코드 = 'A0101135000056' and 평형 = '59' and 평형타입 = 'A' and 인터넷매물 between '1' and '3' > where 인터넷매물 = 1 and 아파트시세코드 = 'A0101135000056' and 평형 = '59' (인터넷매물 = 2에 대한 전체 인덱스 스캔) where 인터넷매물 = 3 and 아파트시세코드 = 'A0101135000056' and 평형 = '59' > 인덱스 선두 컬럼 인터넷 매물에 between 연산자 사용하면 나머지 조건 레코드들이 흩어져 있게 되고 비효율 발생 |
Between 을 In-List로 전환
| 인덱스: 인터넷매물+아파트시세코드+평형+평형타입 where 인터넷매물 in ('1','2','3') and 아파트시세코드 = 'A0101135000056' and 평형 = '59' and 평형타입 = 'A' > where 인터넷매물 = '1' and 아파트시세코드 = 'A0101135000056' and 평형 = '59' and 평형타입 = 'A' union all where 인터넷매물 = '2' and 아파트시세코드 = 'A0101135000056' and 평형 = '59' and 평형타입 = 'A' union all where 인터넷매물 = '3' and 아파트시세코드 = 'A0101135000056' and 평형 = '59' and 평형타입 = 'A' > in-list 개수만큼 union all 브랜치가 생성되고 브랜치마다 = 조건으로 검색된다. > 주의할점 : in-list 개수가 많지 않아야한다. 선택되는 레코드들이 멀리 떨어져있을떄 유용하다. |
Index Scip Scan 활용
| 인덱스1: 판매구분+판매월 인덱스2: 판매월+판매구분 데이터 분포도 예시  select count(*) from 월별고객집계 t where 판매구분 = 'A' and 판매월 between '201801' and '201812' > 인덱스 액세스 사용 효율화 좋음 select /*+ index(t 인덱스2) */ count(*) from 월별고객집계 t where 판매구분 = 'A' and 판매월 between '201801' and '201812' > 인덱스2 사용, 판매월 전체 스캔 후 버리는 레코드 많음 효율화 나쁨 select /*+ index(t 인덱스2) */ count(*) from 월별고객집계 t where 판매구분 = 'A' and 판매월 in ('201801','201802','201803','201804','201805','201806','201807','201808','201809','201810','201811','201812') > 인덱스2 사용, In-list 방식으로 사용 효율화 중간 select /*+ index_ss(t 인덱스2) */ count(*) from 월별고객집계 t where 판매구분 = 'A' and 판매월 between '201801' and '201812' > 인덱스2 사용, 인덱스 스킵스캔 힌트 사용, 효율화 좋은편 |
In조건은 '='인가
| 고객별 평균 카디널리티 = 3 (고객별로 평균 3건 상품 가입) select * from 고객별가입상품 where 고객번호 = '000021201' and 상품ID in ('VH000037','VH000041','VH000050') |
|
 인덱스: 상품ID+고객번호 |
 인덱스: 고객번호+상품ID |
| 인덱스 리프 블록 예시 | |
| 상품ID 별로 인덱스 리프 블록이 멀리 떨어져 있기 때문에 in-list 방식으로 풀리는게 유리하다. in 조건이 = 조건이 됐다. |
in-list 방식으로 풀 경우 같은 블록을 3번탐색하기 위해 9번 읽는다.(루트+브랜치포함) in-list 방식으로 풀지 않을 경우 상품ID는 필터 처리 한다. |
| select * from 고객별가입상품 where 고객번호 = :cust_no and 상품ID = 'VH000037' union all select * from 고객별가입상품 where 고객번호 = :cust_no and 상품ID = 'VH000041' union all select * from 고객별가입상품 where 고객번호 = :cust_no and 상품ID = 'VH000050' |
N/A |
Num_Index_Keys 힌트 활용
| num_index_keys ( table index num ) = num번째 컬럼만 엑세스 조건으로 사용 인덱스1 : 고객번호 + 상품ID 고객번호만 인덱스 액세스 조건으로 사용하려면 num_index_keys(a 인덱스1 1) |
Between과 like 스캔 범위 비교
| like 와 between은 둘 다 범위검색 조건이며 비효율 원리가 똑같이 적용되지만 조건절 값에 따라 인덱스 스캔량이 다르다. like 보다 between을 사용하는게 낫다. 인덱스 : 판매월+판매구분 |
|
| 조건절1 where 판매월 between '201901' and '201912' and 판매구분 = 'B' |
조건절2 where 판매월 like '2019%' and 판매구분 = 'B' |
| 조건절3 where 판매월 between '201901' and '201912' and 판매구분 = 'A' |
조건절4 where 판매월 like '2019%' and 판매구분 = 'A' |
범위검색 조건을 남용할 떄 생기는 비효율
3.4 인덱스 설계
'오라클 > 튜닝' 카테고리의 다른 글
| 6장. DML 튜닝 (0) | 2022.06.26 |
|---|---|
| 5장. 소트 튜닝 (0) | 2022.06.26 |
| 4장. 조인 튜닝 (0) | 2022.06.26 |
| 2장. 인덱스 기본 (0) | 2022.06.18 |
| 1장. SQL 처리 과정과 I/O (0) | 2022.06.18 |